NVIDIA RIVA
NVIDIA® Riva is a GPU-accelerated SDK for building Speech AI applications that are customized for your use case and deliver real-time performance.
Riva offers pretrained speech models in NVIDIA NGC™ that can be fine-tuned with the NVIDIA NeMo on a custom data set, accelerating the development of domain-specific models by 10x.
Models can be easily exported, optimized, and deployed as a speech service on premises or in the cloud with a single command using Helm charts.
Riva’s high-performance inference is powered by NVIDIA TensorRT™ optimizations and served using the NVIDIA Triton™ Inference Server, which are both part of the NVIDIA AI platform.
Riva services are available as gRPC-based microservices for low-latency streaming, as well as high-throughput offline use cases.
Riva is fully containerized and can easily scale to hundreds and thousands of parallel streams.
Deployment
The guide to deploy Riva on Kubernetes has to be adapted for OpenShift. Here are the different steps.
Prerequisites
- You have access and are logged into NVIDIA NGC. For step-by-step instructions, refer to the NGC Getting Started Guide. Specifically you will need your API Key from NVIDIA NGC.
- You have at least one worker node with an NVIDIA Volta™, NVIDIA Turing™, or an NVIDIA Ampere architecture-based GPU. For more information, refer to the Support Matrix.
- The Node Feature Discovery and the NVIDIA operators have been properly installed and configured on your OpenShift Cluster to enable your GPU(s). Full instructions here
- The Pod that will be deployed will consume about 10GB of RAM. Make sure you have enough resources on your node (on top of the GPU itself), and you don't have limits in place that would restrict this. GPU memory consumption will be about 12GB with all models loaded.
Installation
Included in the NGC Helm Repository is a chart designed to automate deployment to a Kubernetes cluster. This chart must be modified for OpenShift.
The Riva Speech AI Helm Chart deploys the ASR, NLP, and TTS services automatically. The Helm chart performs a number of functions:
- Pulls Docker images from NGC for the Riva Speech AI server and utility containers for downloading and converting models.
- Downloads the requested model artifacts from NGC as configured in the values.yaml file.
- Generates the Triton Inference Server model repository.
- Starts the Riva Speech AI server as configured in a Kubernetes pod.
- Exposes the Riva Speech AI server as a configured service.
Examples of pretrained models are released with Riva for each of the services. The Helm chart comes preconfigured for downloading and deploying all of these models.
Installation Steps:
-
Download the Helm chart
export NGC_API_KEY=<your_api_key> helm fetch https://helm.ngc.nvidia.com/nvidia/riva/charts/riva-api-2.11.0.tgz \ --username=\$oauthtoken --password=$NGC_API_KEY --untar -
Switch to the newly created folder,
riva-api -
In the
templatesfolder, modify the filedeployment.yaml. For both the containerriva-speech-apiand the initContainerriva-model-inityou must add the following security context information:securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] seccompProfile: type: "RuntimeDefault" runAsNonRoot: true -
The file
deployment.yamlshould now look like this:... apiVersion: apps/v1 kind: Deployment metadata: name: {{ template "riva-server.fullname" . }} ... spec: ... template: ... spec: containers: - name: riva-speech-api securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] seccompProfile: type: "RuntimeDefault" runAsNonRoot: true image: {{ $server_image }} ... initContainers: - name: riva-model-init securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] seccompProfile: type: "RuntimeDefault" runAsNonRoot: true image: {{ $servicemaker_image }} ... -
At the root of
riva-api, modify the filevalues.yaml:-
You will need to convert your API Key to a password value. In a Terminal run:
echo -n $NGC_API_KEY | base64 -w0 -
In the
ngcCredentialssection ovvalues.yaml, enter the password you obtained above and your email - In the
modelRepoGeneratorsection, for themodelDeployKeyvalue, enterdGx0X2VuY29kZQ==. (This value is obtained from the commandecho -n tlt_encode | base64 -w0. - In the
persistentVolumeClaimsection, setusePVCto true. This is very important as it will disable the hostPath configuration for storage that is not permitted by default on OpenShift. - If you don't have a storageClass set as default, or want to you another one, enter the name of the class you want to use in
storageClassName. Otherwise leave this field empty and the default class will be used. - Optionally, modify the storageSize.
- Leave the
ingresssection as is, we will create an OpenShift Route later. - Optionally you can modify other values in the file to enable/disable certain models, or modify their configuration.
-
-
Log into your OpenShift cluster from a Terminal, and create a project
riva-api:oc new-project riva-api -
Move up one folder (so outside of the
riva-apifolder), and install NVIDIA Riva with the modified Helm chart:helm install riva-api riva-api
The deployment will now start.
Info
Beware that the deployment can be really long the first time, about 45mn if you have all the models and features selected. Containers and models have to be downloaded and configured. Please be patient...
Usage
The Helm chart had automatically created a Service, riva-api in the namespace where you have deployed it. If you followed this guide, this should also be riva-api. So within the OpenShift cluster, the API is accessible at riva-api.riva-api.svc.cluster.local.
Different ports are accessible:
- http (8000): HTTP port of the Triton server.
- grpc (8001): gRPC port of the Triton server.
- metrics (8002): port for the metrics of the Triton server.
- speech-grpc (50051): gRPC port of the Speech that exposes directly the different services you can use. This is normally the one that you will use.
If you want to use the API outside of the OpenShift cluster, you will have to create one or multiple Routes to those different endpoints.
Example
- On the same cluster where NVIDIA Riva is deployed, deploy RHOAI or ODH and launch a Notebook (Standard DataScience is enough).
- Clone the NVIDIA Riva tutorials repository at https://github.com/nvidia-riva/tutorials
- Open a Terminal and install the client with
pip install nvidia-riva-client:
(depending on the base image you used this may yield errors that you can ignore most of times).
- In the
tutorialsfolder, open the notebookasr-basics.ipynb. - In the cell that defines the uri of the API server, modify the default (localhost) for the address of the API server:
riva-api.riva-api.svc.cluster.local

- Run the notebook!
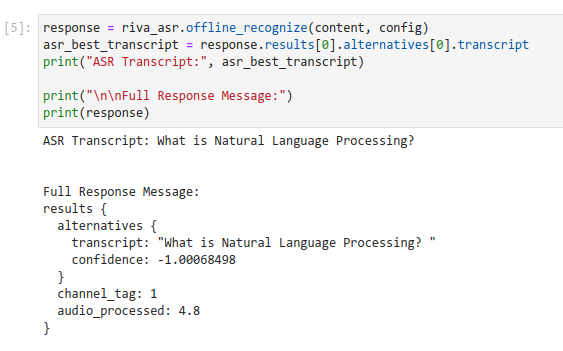
Note
In this example, only the first part of the notebook will work as only the English models have been deployed. You would have to adapt the configuration for other languages.