Chat with your Documentation
If you want to learn more about LLMs and how to serve them, please read the LLM Serving documentation first.
RAG Chatbot Full Walkthrough
Although the available code is normally pretty well documented, especially the notebooks, giving a full overview will surely help you understand how all of the different elements fit together.
For this walkthrough we will be using this application, which is a RAG-based Chatbot that will use a Milvus vector store, vLLM for LLM serving, Langchain as the "glue" between those components, and Gradio as the UI engine.
Requirements
- An OpenShift cluster with RHOAI or ODH deployed.
- A node with a GPU card. For the model we will use, 24GB memory on the GPU (VRAM) is necessary. If you have less than that you can either use quantization when loading the model, use an already quantized model (results may vary as they are not all compatible with the model server), or choose another compatible smaller model.
Model Serving
Deploy vLLM Model Serving instance in the OpenAI compatible API mode, either:
In both cases, make sure you deploy the model mistralai/Mistral-7B-Instruct-v0.2.
Vector Store
Milvus deployment
For our RAG we will need a Vector Database to store the Embeddings of the different documents. In this example we are using Milvus.
Deployment instructions specific to OpenShift are available here.
After you follow those instructions you should have a Milvus instance ready to be populated with documents.
Document ingestion
In this notebook you will find detailed instructions on how to ingest different types of documents: PDFs first, then Web pages.
The examples are based on RHOAI documentation, but of course we encourage you to use your own documentation. After all that's the purpose of all of this!
This other notebook will allow you to execute simple queries against your Vector Store to make sure it works alright.
Note
Those notebooks are using the NomicAI Embeddings to create and query the collection. If you want to use the default embeddings from Langchain, other notebooks are available. They have the same name, just without the -nomic at the end.
Testing
Now let's put all of this together!
This notebook will be used to create a RAG solution leveraging the LLM and the Vector Store we just populated. Don't forget to enter the relevant information about your Model Server (the Inference URL and model name), and about your Vector store (connection information and collection name) on the third cell.
You can also adjust other parameters as you see fit.
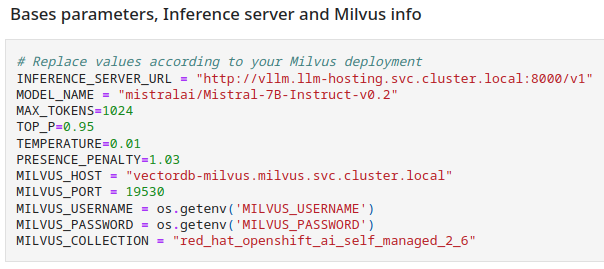
- It will first initialize a connection to the vector database (embeddings are necessary for the Retriever to "understand" what is stored in the database):
model_kwargs = {'trust_remote_code': True}
embeddings = HuggingFaceEmbeddings(
model_name="nomic-ai/nomic-embed-text-v1",
model_kwargs=model_kwargs,
show_progress=False
)
- A prompt template is then defined. You can see that we will give it specific instructions on how the model must answer. This is necessary if you want to keep it focused on its task and not say anything that may not be appropriate (on top of getting you fired!). The format of this prompt is originally the one used for Llama2, but Mistral uses the same one. You may have to adapt this format if you use another model.
template="""<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant named HatBot answering questions.
You will be given a question you need to answer, and a context to provide you with information. You must answer the question based as much as possible on this context.
Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
Context:
{context}
Question: {question} [/INST]
"""
- Now we will define the LLM connection itself. As you can see there are many parameters you can define that will modify how the model will answer. Details on those parameters are available here.
llm = VLLMOpenAI(
openai_api_key="EMPTY",
openai_api_base=INFERENCE_SERVER_URL,
model_name=MODEL_NAME,
max_tokens=MAX_TOKENS,
top_p=TOP_P,
temperature=TEMPERATURE,
presence_penalty=PRESENCE_PENALTY,
streaming=True,
verbose=False,
callbacks=[StreamingStdOutCallbackHandler()]
)
- And finally we can tie it all together with a specific chain, RetrievalQA:
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=store.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True
)
- That's it! We can now use this chain to send queries. The retriever will look for relevant documents in the Vector Store, their content will be injected automatically in the prompt, and the LLM will try to create a valid answer based on its own knowledge and this content:
question = "How can I create a Data Science Project?"
result = qa_chain.invoke({"query": question})
- The last cell in the notebook will simply filter for duplicates in the sources that were returned in the
result, and display them:
def remove_duplicates(input_list):
unique_list = []
for item in input_list:
if item.metadata['source'] not in unique_list:
unique_list.append(item.metadata['source'])
return unique_list
results = remove_duplicates(result['source_documents'])
for s in results:
print(s)
Application
Notebooks are great and everything, but it's not what you want to show to your users. I hope...
So instead, here is a simple UI that implements mostly the same code we used in the notebooks.
The deployment is already explained in the repo and pretty straightforward as the application will only "consume" the same Vector Store and LLM Serving we have used in the notebooks. However I will point out some specificities:
- This implementation allows you to have different collections in Milvus you can query from. This is fully configurable, you can create as many collections as you want and add them to the application.
- The code is more complicated than the notebooks as it allows for multiple users to use the application simultaneously. They can all use a different collection, ask questions at the same time, they stay fully isolated. The limitation is the memory you have.
- Most (if not all) parameters are configurable. They are all described in the README file.
Some info on the code itself (app.py):
load_dotenv, along with theenv.examplefile (once renamed.env) will allow you to develop locally.- As normally your Milvus instance won't be exposed externally to OpenShift, if you want to develop locally you may want to open a tunnel to it with
oc port-forward Service/milvus-service 19530:19530(replace with the name of the Milvus Service along with the ports if you change them). You can use the same technique for the LLM endpoint if you have not exposed it as a route. - The class
QueueCallbackwas necessary because thevLLMOpenAIlibrary used to query the model does not return an iterator in the format Langchain expects it (at the time of this writing). Instead, this implementation of the Callback functions for the LLM puts the new tokens in a Queue (L43) that is then retrieved from continuously (L65), with the content being yielded for display. This is a little bit convoluted, but the whole stack is still in full development, so sometimes you have to be creative... - The default Milvus Retriever (same for almost all vector databases in Langchain) does not allow to filter on the score. This means that whatever your query, some documents will always be fetched and passed into the context. This is an unwanted behavior if the query has no relation to the knowledge base you are using. So I created a custom Retriever Class, in the file
milvus_retriever_with_score_threshold.pythat allows to filter the documents according to score. NOTE: this a similarity search with a cosine score, so the lesser, the better. The threshold calculation is "no more than...". - Gradio configuration is pretty straightforward trough the ChatInterface component, only hiding some buttons, adding an avatar image for the bot,... The only notable thing is the use of a State variable for the selected collection so that a switch from one collection to the other is not applied to all users (this is an early mistake I made 😊) .
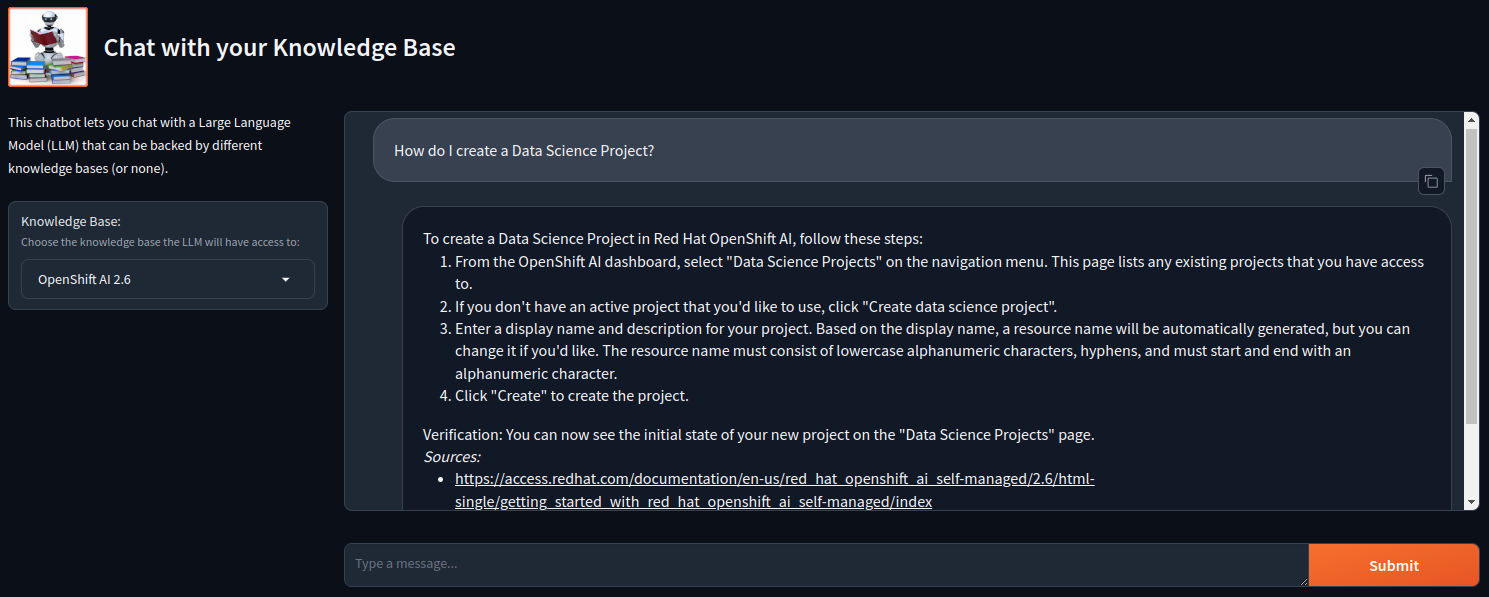
Here is what you RAG-based Chatbot should look like: