Data Science Pipeline
What is it?
OpenShift AI allows building of machine line workflows with a data science pipeline. From OpenShift AI version 2.9, data science pipelines are based on KubeFlow Pipelines (KFP) version 2.0.
What is Kubeflow Pipelines?
Kubeflow Pipelines (KFP) is a platform for building and deploying portable and scalable machine learning (ML) workflows using Docker containers.
With KFP you can author components and pipelines using the KFP Python SDK, compile pipelines to an intermediate representation YAML, and submit the pipeline to run on a KFP-conformant backend.
The current version of KFP 2.0 in OpenShift AI uses Argo Workflow as the backend.
Why do I see OpenShift Pipeline in this example?
The example uses OpenShift Pipeline (Tekton) to compile the pipeline into an intermediate representation (IR) YAML and submit it to the Kubeflow Pipeline server (instead of doing it from your Jupyter environment using Elyra, or importing it directly through the Dashboard).
The Tekton pipeline has 2 main tasks:
- git-clone
- execute-kubeflow-pipeline to compile and submit the pipeline
Example
Architectural Diagram
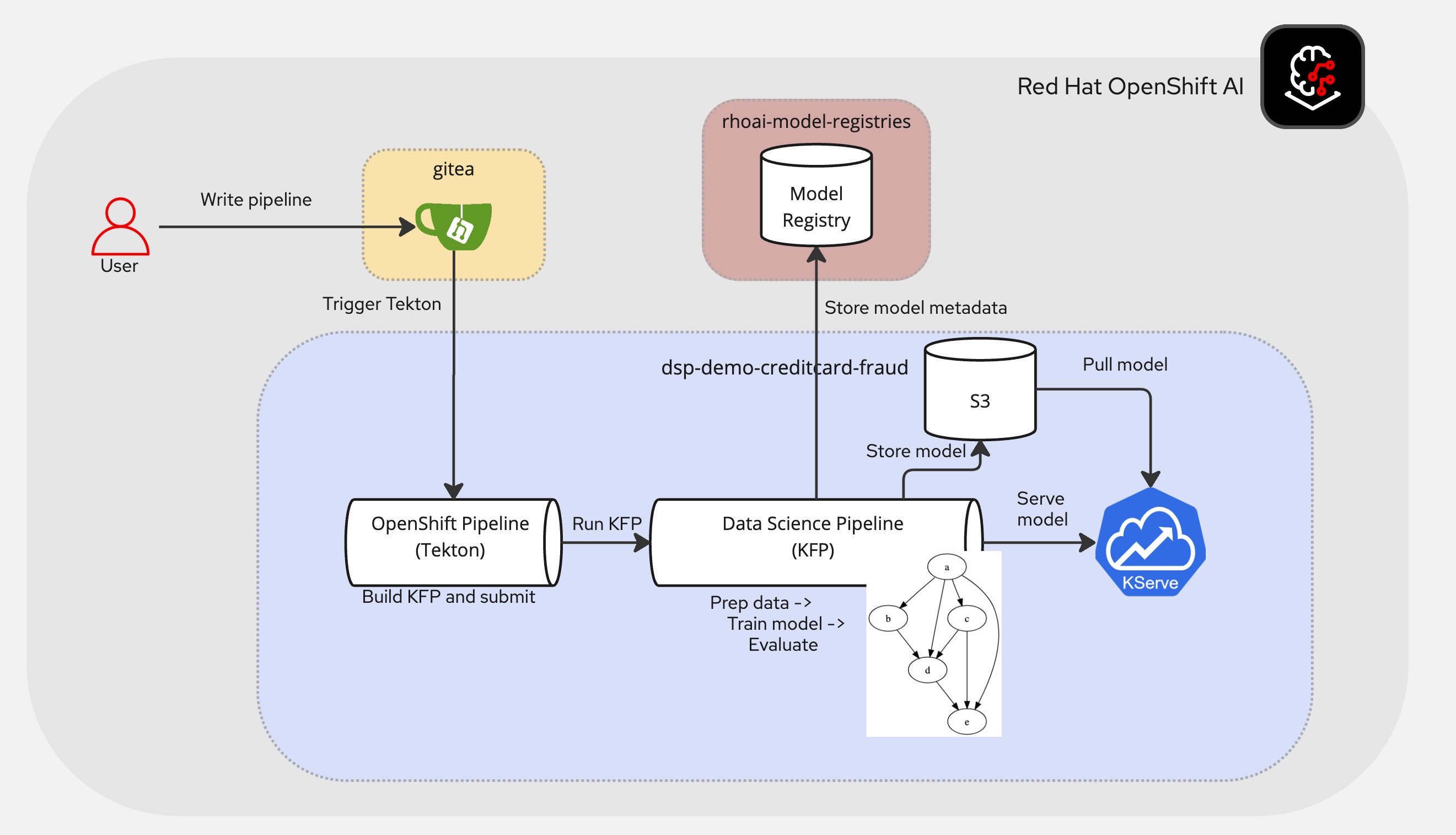
The demo uses the following components:
| Component | Descrioption |
|---|---|
| Gitea | To store pipeline source code |
| Model Registry | To store model metadata |
| OpenShift Pipelines | Using Tekton to build the pipeline |
| Data Science Pipeline | To run the pipeline using KFP |
| Minio | S3 bucket to store the model |
| KServe | To serve the model |
Prerequisite
You will need OpenShift 2.15 installed with ModelRegistry set to Managed. In 2.15, the model registry feature is currently in Tech Preview.
Running the Example
The sample code is available here.